Understand Autoencoder(2):Variational Autoencoder
Published:
以下将分为6个部分介绍:
- vae结构框架
- vae与ae区别
- 提及一下为什么要采样
- 如何优化
- vae应用
- vae生成/抽象看待vae学习
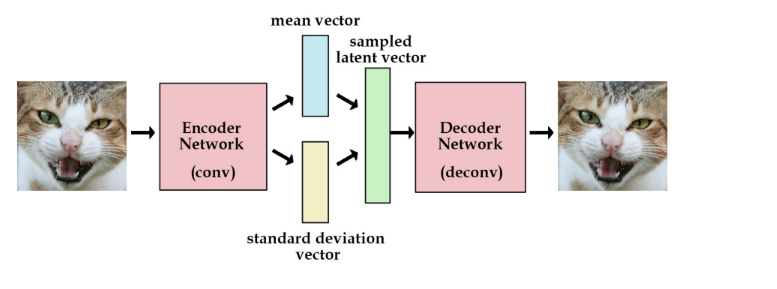
1.框架:
先来看一下VAE的结构框架,并先预告一下结论: VAE 包括 encoder (模块 1)和 decoder(模块 4) 两个神经网络。两者通过模块 2、3 连接成一个大网络。利益于 reparemeterization 技巧,我们可以使用常规的 SGD 来训练网络。
2.区别:
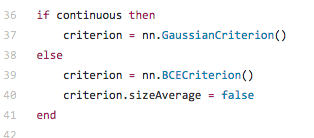
个人认为和ae在本质上的区别在于z code的生成方式,以及loss的定义. 先看一下torch vae中的代码对loss的定义:
以及梯度的回传:

所以结论为:
1)在ae中,z是encoder直接的显式输出的神经元向量,decoder出来的衡量为距离.
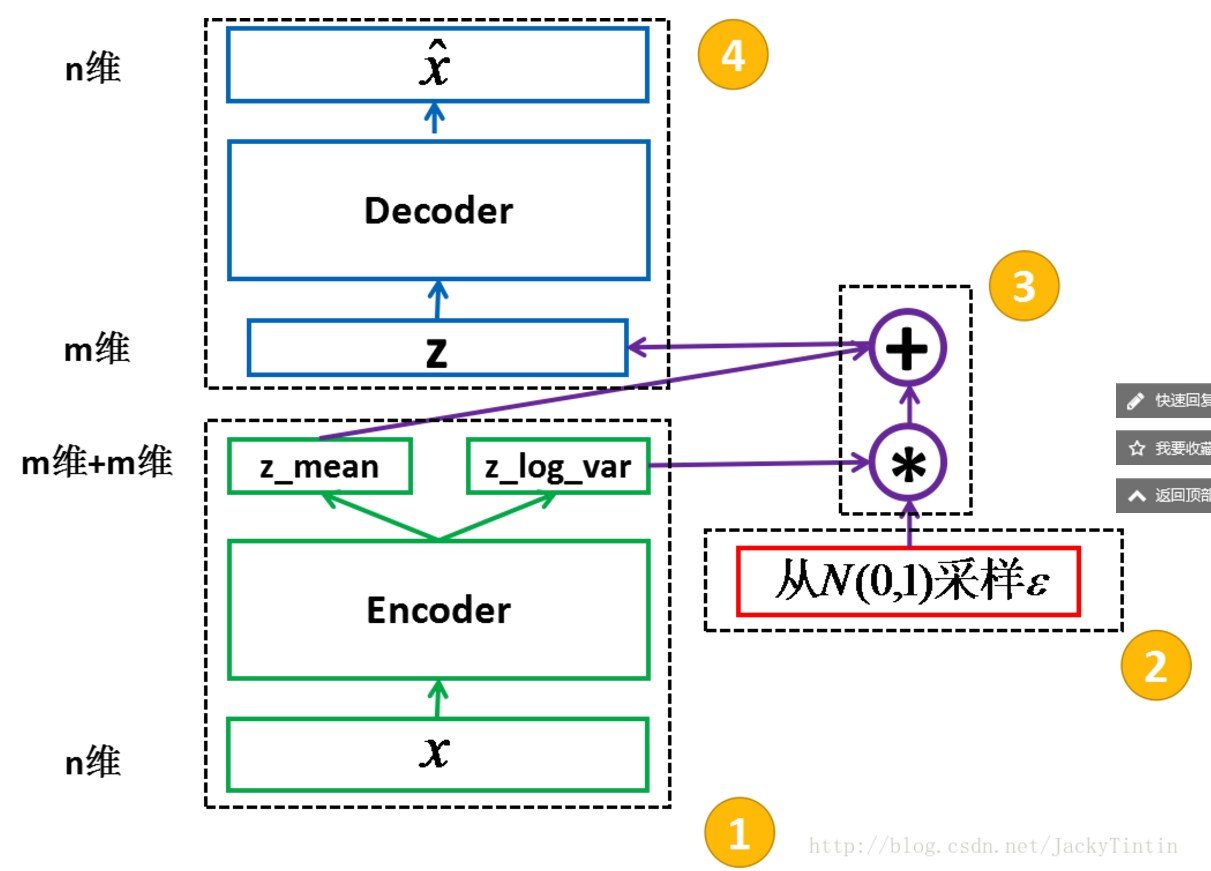
2)在vae中,encoder 的输出(2×m 个数)视作分别为 m 个高斯分布的均值(z_mean)和方差的对数(z_log_var)而输入decoder的z是根据均值和方差生成服从相应高斯分布的随机数的一个向量.对编码器添加约束,就是强迫它产生服从单位高斯分布的潜在变量。正式这种约束,把VAE和标准自编码器给区分开来了。 如下:
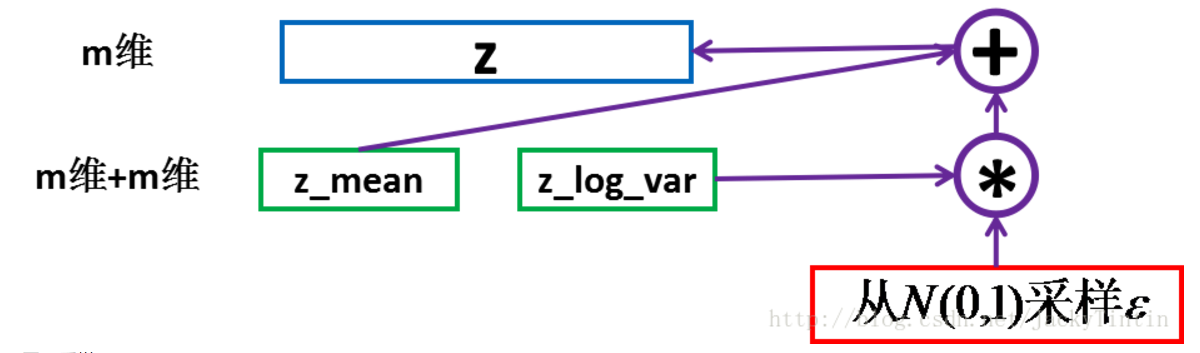
我们计算解码器的loss时,我们就可以从标准差向量中采样,然后加到我们的均值向量上,就得到了编码去需要的潜在变量。

同时,decoder出来的衡量为交叉熵加kl散度:
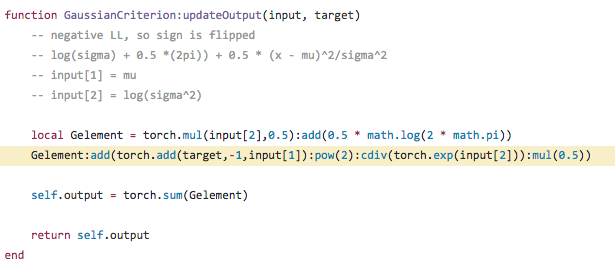
3.为什么要采样:
为了SGD能够使用。
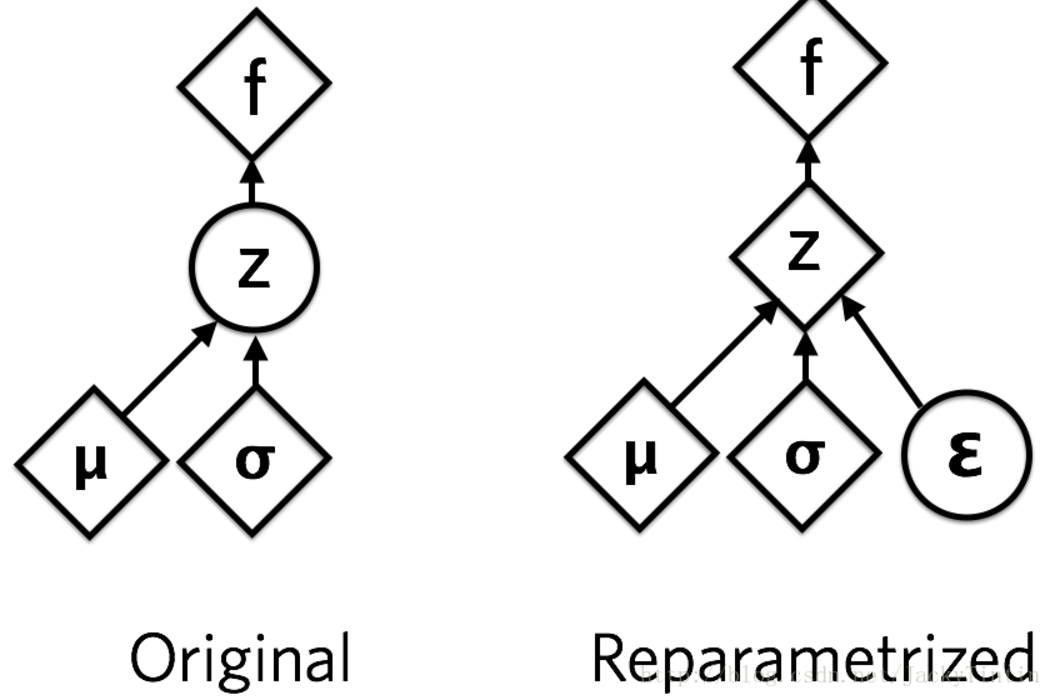
运用了 reparemerization 的技巧。由于 z∼N(μ,σ),我们应该从 N(μ,σ) 采样,但这个采样操作对 μ 和 σ 是不可导的,导致常规的通过误差反传的梯度下降法(GD)不能使用。通过 reparemerization,我们首先从 N(0,1) 上采样 ϵ,然后,z=σ⋅ϵ+μ。这样,z∼N(μ,σ),而且,从 encoder 输出到 z,只涉及线性操作,(ϵ 对神经网络而言只是常数),因此,可以正常使用 GD 进行优化。
4.如何优化:
1)首先明确目标:
encoder 和 decoder 组合在一起,我们能够对每个 x∈X,输出一个相同维度的 x̂ 。我们目标是,令 x̂ 与 x 自身尽量的接近。即 x 经过编码(encode)后,能够通过解码(decode)尽可能多的恢复出原来的信息。 (注:严格而言,按照模型的假设,我们要优化的并不是 x 与 x̂ 之间的距离,而是要最大化 x 的似然。即若是encoder/decoder的编码过程中,编码满足的是一个x 与 x̂ 之间最大似然概率分布.)
2)定义损失函数以及约束:
不同的损失函数,对应着不是 p(x|z) 的不同概率分布假设,由于 x∈[0,1],因此,我们用交叉熵(cross entropy)度量 x 与 x̂ 差异,xent 越小,x 与 x̂ 越接近。
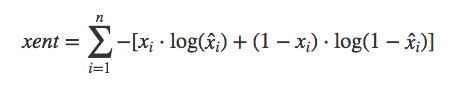
我们也可以用均方误差来度量,mse 越小,两者越接近。
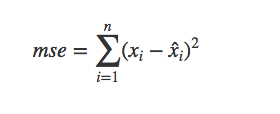
3)训练过程中的附加约束KL散度
训练过程中,输出即是输入,这便是 VAE 中 AE(autoencoder,自编码)的含义。另外,我们需要对 encoder 的输出 z_mean(μ)及 z_log_var(logσ2)加以约束。这里使用的是 KL 散度。
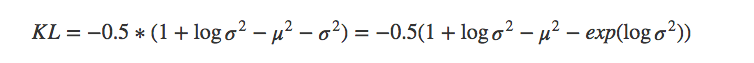
4)总的优化目标:
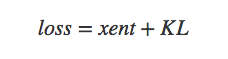
5.vae应用:
1)相似数据生成:
由于我们指定 p(z) 标准正态分布,再接合已经训练和的 decoder (p(x|z)),就可以进行采样,生成类似但不同于训练集数据的新样本。
下图是基于训练出来的 decoder,采样生成的图像x̂ 。 严格来说,生成下图的代码并不是采样,而是 E[x|z] 。伯努力分布和高斯分布的期望,正好是 decocder 的输出 x̂。

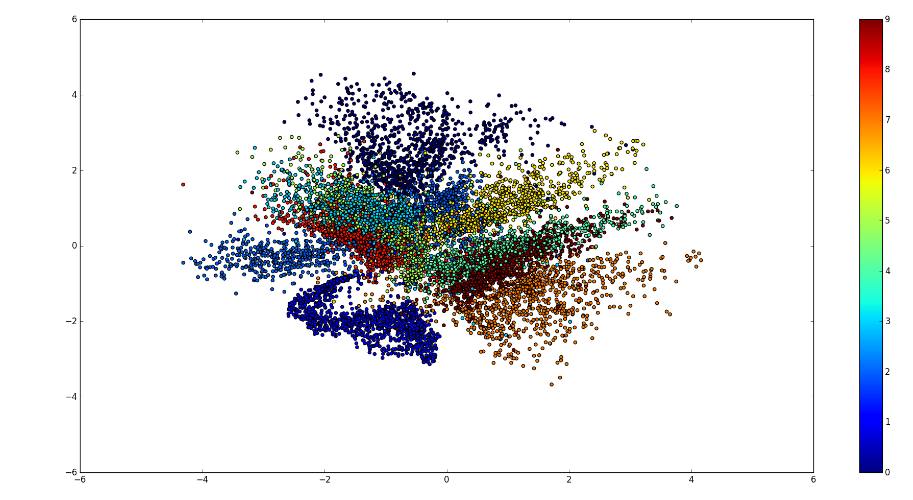
2)高维数据可视化:
encoder 可以将数据 x,映射到更低维的 z 空间,如果是2维或3维,就可以直观的展示出来。
3) 缺失数据补充:
对许多现实问题,样本点的各维数据存在相关性。因此,在部分维度缺失或不准确的情况,有可能通过相关信息得到填补。下图展示一个简单的数据填补的实例。其中,第一行为原图,第二行为人行中间某些像素的缺失图,第三行为利用 VAE 模型恢复的图。

4)半监督学习:
相比于高成本的有标注的数据,无标注数据更容易获取。半监督学习试图只用一小部分有标注的数据加上大量无标注数据,来学习到一个较好预测模型(分类或回归)。
VAE 是无监督的,而且也可以学习到较好的特征表征,因此,可以被用来作无监督学习。
6.vae学习到的问题抽象:
1)模型结构类别ae:
从模型结构(以及名字)上看,VAE和自编码器(audoencoder)非常的像。特别的,VAE 和 CAE(constractive AE)非常相似,两者都对隐层输出增加长约束。而 VAE 在隐层的采样过程,起到和 dropout 类似的正则化作用。
2)学习过程中,实际为学习一个分布
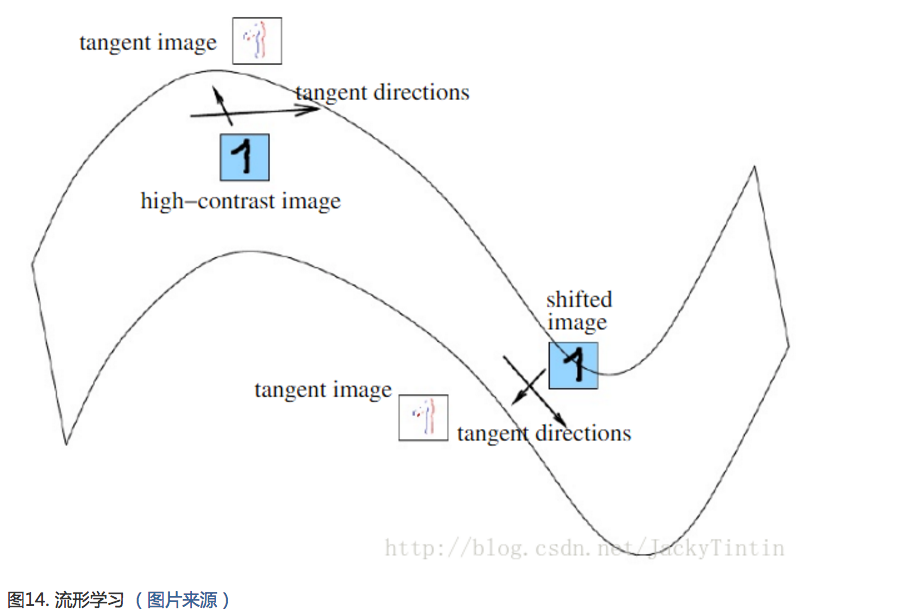
数据虽然高维,但相似数据可能分布在高维空间的某个流形上(例如下图)。而特征学习就要显式或隐式地学习到这种流形。正是这种流形分布,我们才能从低的隐变量恢复出高维的观测变量。如上面回复mnist数据,相似的隐变量对应的观测变量确实比较像,并且这样相似性是平滑的变化。
3) 数据生成的衡量: 举个例子, 当我们计算解码器的loss时,我们就可以从标准差向量中采样,然后加到我们的均值向量上,就得到了编码去需要的潜在变量, 实现如下图:

VAE除了能让我们能够自己产生随机的潜在变量,这种约束也能提高网络的产生图片的能力。
为了更加形象,我们可以认为潜在变量是一种数据的转换。 我们假设我们有一堆实数在区间[0, 10]上,每个实数对应一个物体名字。比如,5.43对应着苹果,5.44对应着香蕉。当有个人给你个5.43,你就知道这是代表着苹果。我们能用这种方法够编码无穷多的物体,因为[0, 10]之间的实数有无穷多个。
但是,如果某人给你一个实数的时候其实是加了高斯噪声的呢?比如你接受到了5.43,原始的数值可能是 [4.4 ~ 6.4]之间的任意一个数,真实值可能是5.44(香蕉)。
如果给的方差越大,那么这个平均值向量所携带的可用信息就越少。现在,我们可以把这种逻辑用在编码器和解码器上。
编码越有效,那么标准差向量就越能趋近于标准高斯分布的单位标准差。 (以0为均数、以1为标准差的正态分布,记为N(0,1)) 这种约束迫使编码器更加高效,并能够产生信息丰富的潜在变量。这也提高了产生图片的性能。而且我们的潜变量不仅可以随机产生,也能从未经过训练的图片输入编码器后产生。
reference material: http://blog.csdn.net/jackytintin/article/details/53641885



Leave a Comment