FCN: Fully Convolutional Networks for Semantic Segmentation
Published:
Reference Materials of Fully Convolutional Networks:
这里简略地对fcn这篇文章的keypoint做个快速的总结,加深对fcn的一个理解:
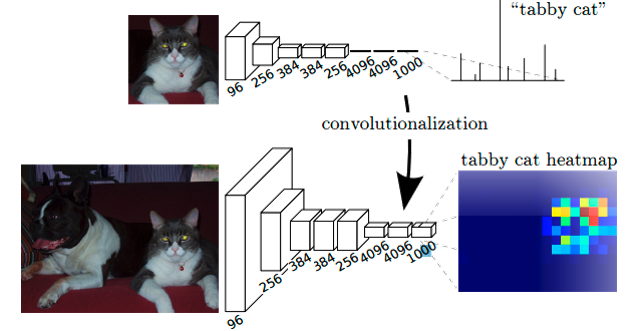
一、简单的介绍一下上图的实际含义,我们已经有一个CNN模型,首先要把CNN的全连接层看成是卷积层,卷积模板大小就是输入的特征map的大小,也就是说把全连接网络看成是对整张输入map做卷积,全连接层分别有4096个6*6的卷积核,4096个1*1的卷积核,1000个1*1的卷积核,接下来就要对这1000个1*1的输出,做upsampling,得到1000个原图大小(如32*32)的输出,这些输出合并后,得到上图所示的heatmap。
二、那么如何通过upsampling得到dense prediction呢,在Fully Convolutional Networks for Semantic Segmentation这篇论文中,提到了大概三种方案。
1)Shift-and-Stitch:
设原图与FCN所得输出图之间的降采样因子是f,那么对于原图的每个ff的区域(不重叠)“shift the input x pixels to the right and y pixels down for every (x,y) ,0 < x,y < f.”* 把这个f*f区域对应的output作为此时区域中心点像素对应的output,这样就对每个f*f的区域得到了f^2个output,也就是每个像素都能对应一个output,所以成为了dense prediction。
2)Filter rarefaction:
就是放大CNN网络中的subsampling层的filter的尺寸,得到新的filter
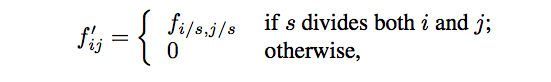
其中s是subsampling的滑动步长,这个新filter的滑动步长要设为1,这样的话,subsampling就没有缩小图像尺寸,最后可以得到dense prediction。
以上两种方法作者都没有采用,主要是因为这两种方法都是trad-off的,原因是:
1.对于第一种方法,虽然receptive fileds没有变小,但是由于原图被划分成f*f的区域输入网络,使得filters无法感受更精细的信息。
2.对于第二种方法, 下采样的功能被减弱,使得更细节的信息能被filter看到,但是receptive fileds会相对变小,可能会损失全局信息,且会对卷积层引入更多运算。
3.实现反卷积层:其实就是upsamping,只不过其中卷积运算的参数和CNN的参数一样是在训练FCN模型的过程中通过bp算法学习得到。

3)实现反卷积层:其实就是upsamping,只不过其中卷积运算的参数和CNN的参数一样是在训练FCN模型的过程中通过bp算法学习得到。

tricks:
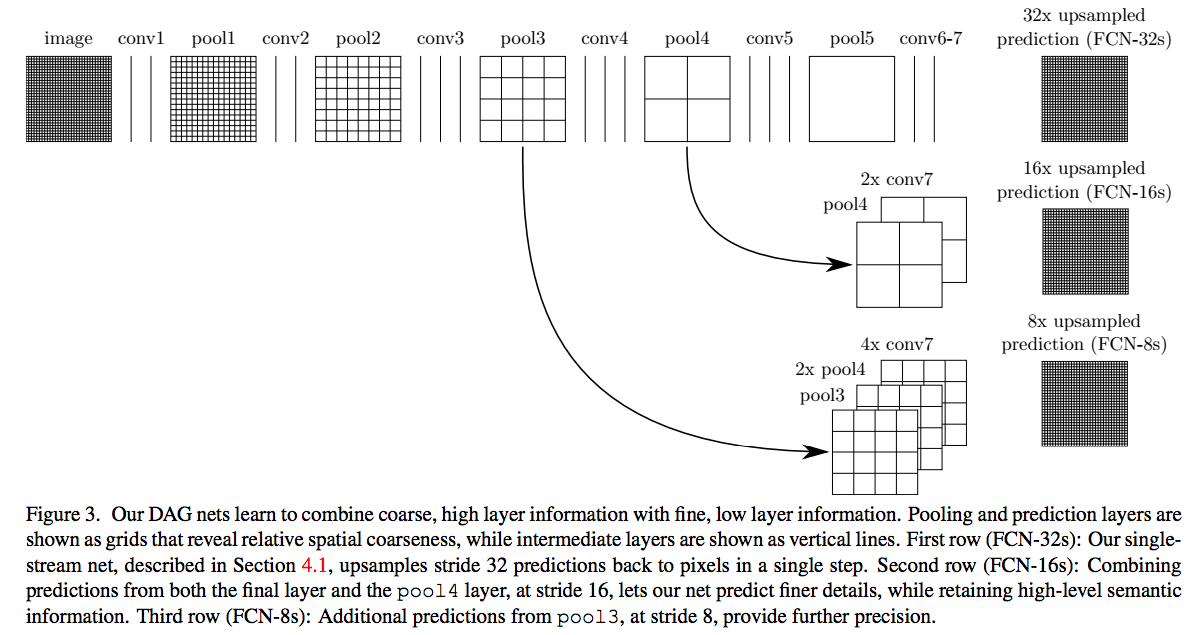
以上是对CNN的结果做处理,得到了dense prediction,而作者在试验中发现,得到的分割结果比较粗糙,所以考虑加入更多前层的细节信息,也就是把倒数第几层的输出和最后的输出做一个fusion,实际上也就是加和。这个trick实际上在很多task都可以参考, 分割任务上CVPR去年排名最好的PSPNet和ICNNet等分割网络就是延续并拓展了类似的思想。
这样就得到第二行和第三行的结果,实验表明,这样的分割结果更细致更准确。在逐层fusion的过程中,做到第三行再往下,结果又会变差,所以作者做到这里就停了。可以看到如上三行的对应的结果:
最后顺带提一下发展,从FCN之后,依次发展出了segnet/deconvnet的对称结构,以及deeplab通过设计atrous convolution来提高感受野。 这篇文章,就是在这些发展基础上,提出了称之为enet的一个快速,紧凑的模型,请看我下一篇的解析~ E-net:A Deep Neural Network Architecture for Real-Time Semantic Segmentation
reference material: http://blog.csdn.net/tangwei2014/article/details/46882257


Leave a Comment