GAN:F-GAN/EBGAN/infoGAN/GAN+VAE/catGAN/DCGAN/ImprovedGAN
Published:
文章结构:
对比VAE/pixelRNN/GAN缺陷,了解GAN与之相似结构之间存在的缺陷 GAN在2016年的进展方向总结
- 理论框架层面的拓展和改进: f-GAN、EBGAN、infoGAN、GAN+VAE、CatGAN
- 模型改进: loss方面 perceptual loss
- 训练技巧: DCGAN、Improved GAN
1.对比VAE&pixelRNN以及GAN的缺陷:
VAE的缺陷:在最终模拟的概率分布一定会存在一些偏置
pixelRNN的缺陷: 将图像的生成问题转换为像素序列的预测和生成,因此需要对每个像素操作,耗时.

GAN最大的缺陷: 训练过程中的稳定性和收敛性
其训练过程中的稳定性和收敛性难以保证,在2016年有许多相关工作都在尝试解决其训练稳定性问题。 (模型崩塌问题 model collapsed)
2.较为瞩目的工作:
GAN理论层面的改进
- 一类是从第三方的角度,而不是从GAN模型本身,来看待GAN并进行改进和扩展的方法;
- 第二类是从GAN模型框架的稳定性、实用性等角度出发对模型本身进行改进的工作。
f-GAN: 在理解GAN上,将GAN的优化问题求解看作是求解某种divergence的最小化问题。
Detail:
1)提出一个量化距离标准,f-divergence,包括了常见的多种概率分布的距离度量.
2)作者利用GAN模型框架结合不同度量条件,即不同divergence进行图像生成。
其中,在选择KL散度的度量方式时,对比结果如下图所示,可以看出两者的效果其实相差不大。

EBGAN(hinton): 从能量模型的角度来看待GAN的判别器。
EBGAN将判别器看做是一个能量函数,这个能量函数在真实数据域附近的区域中能量值会比较小,而在其他区域(即非真实数据域区域)都拥有较高能量值。
因此,EBGAN中给予GAN一种能量模型的解释,即生成器是以产生能量最小的样本为目的,而判别器则以对这些产生的样本赋予较高的能量为目的。
网络结构:
D的部分用了AE即z(随机向量)进去G生成图像后,不直接用传统方式的判别器进行判别, 使用了AE重新做一个encoder/decoder,然后对target图算mse的loss。
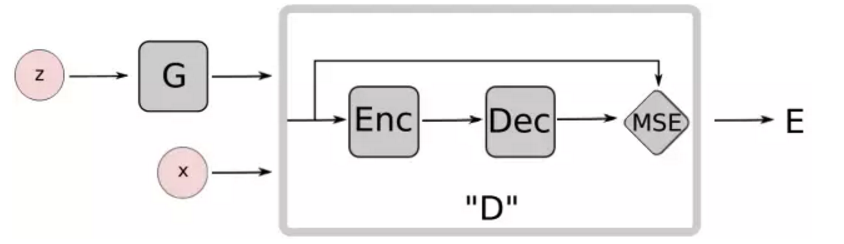
EBGAN比GAN展示出了更稳定的性能,也产生出了更加清晰的图像。

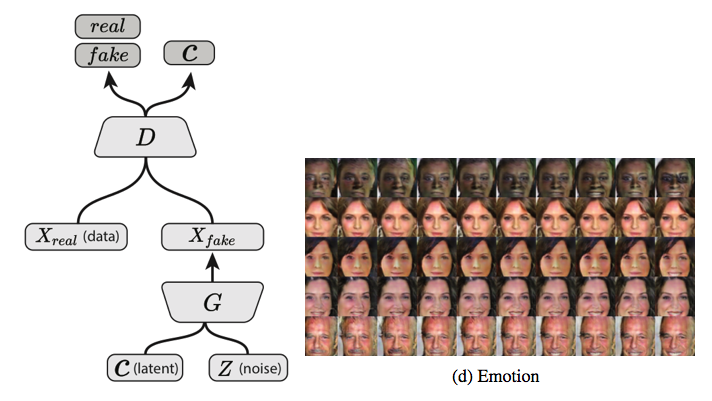
infoGAN: 加入latent code C来使得训练好的网络在生成时是可控的。
网络结构: 在训练GAN的时候,将随机输入的噪声强行拆解为两部分,其中有一部分的可解释的有隐含意义的c。 c可以对应于笔画粗细、图像光照、字体倾斜度等,用C1,C2,…,CL表示,我们称之为latent code 而z则可以认为是剩下的不知道怎么描述的或者说不能明确描述的信息 目标函数:
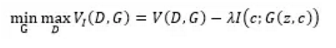
此时生成器的输出就从原来的G(z)变成了G(z,c);
在学习过程中,为了避免学到一些trivial的latent code而忽略了重要的code,文章对原始的GAN目标函数加了一个约束, 即约束latent code c和生成器的输出G(z,c)之间的互信息I(c;G(z,c))越高越好,以此希望能学到比较重要的有意义的codes c
实验: latent code确实学到了一些维度,如对应于图像的角度或光照的因素,也即说明InfoGAN确实学习到了数据中的disentangled的可解释部分的表示。
Detail:
1)潜在编码 latent code c
原来的GAN G的输出为 G(z) 现在改为 G(z,c) / c可以包含多种变量,根据不同的分布
比如在MNIST中,c可以一个值来表示类别,一个高斯分布的值来表示手写体的粗细
2)共同信息 mutual information
如果使用潜在编码c,其实没有监督让网络去使用c。它就往往会被忽略 为了避免这种情况,作者定义了一个熵。作为衡量X,Y两个变量之间 mutual information的程度
I(X;Y) = entropy(X) - entropy(X|Y) = entropy(Y) - entropy(Y|X) 这个值就像条件概率,联系越大的话,这个值应该越小 -新的loss被定义为 old loss - lamda* I(G(z,c);c) 后一项应该需要越来越小。
3)variational mutual information maximisation
就是用一个网络从 G(z,c) 来regress c 可以和D是同一个网络,最后分个叉来回归c。
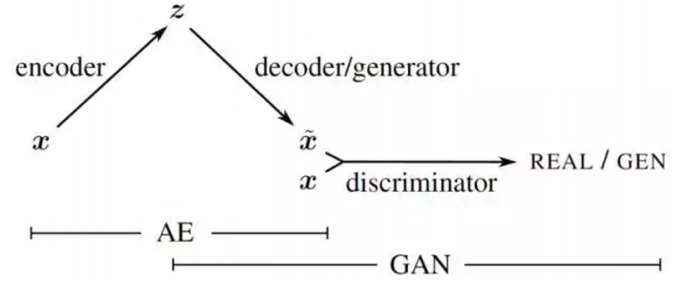
GAN+VAE: (encoder + decoder/generator) 看做一个产生式模型的整体,从而和最后一个部分 (discriminator) 构成了扩展的GAN模型.
将GAN与其它模型结合,综合利用GAN模型与其它模型的优点来完成数据生成任务。
相当于把G的部分改为AE做编解码
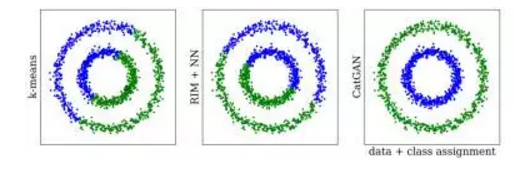
CatGAN: 增加了一个类别损失的约束,也就是添加少量有label的样本来训练。
对于真实的数据,模型希望判别器不仅能具有较大的确信度将其划分为真实样本,同时还有较大的确信度将数据划分到某一个现有的类别中去;
而对于生成数据却不是十分确定要将其划分到哪一个现有的类别,也就是这个不确信度比较大,从而生成器的目标即为产生出那些“将其划分到某一类别中去”的确信度较高的样本,尝试骗过判别器。
接下来,为了衡量这个确信程度,作者用熵来表示,熵值越大,即为越不确定;而熵值越小,则表示越确定。然后,将该确信度目标与原始GAN的真伪鉴别的优化目标结合,即得到了CatGAN的最终优化目标。
对于半监督的情况,即当部分数据有标签时,那么对有标签数据计算交叉熵损失,而对其他数据计算上面的基于熵的损失,然后在原来的目标函数的基础上进行叠加即得
GAN模型层面的改进
- 主要为perceptual loss, 即feature map特征层面上的L1/L2
Perceptual Similarity Metrics (NIPS-2016): 引入feature map loss / l1 loss / gan loss 一起训练
具体来说,在训练GAN时,除了原始GAN中的对抗训练损失,额外加入了两个损失项,共计三个损失项。
可以看出:
1)如果没有对抗损失Ladv,产生的结果非常差;
2)如果没有特征空间的损失项Lfeat,会使产生的图像只有大概的轮廓信息,但会丢失许多细节信息;
3)如果没有图像空间损失Limg,最终产生的结果跟有Limg差不多,但在训练的时候没有这一项的话会使网络更容易不稳定; 而同时利用三项loss的结果则可以相对稳定的产生出较为清晰的图像。

在最近SR的task中,由feature map loss + gan loss + tv loss 基本成为标配.
比如SRCNN中的loss函数:

GAN训练方式的改进
- DCGAN
- Improved GAN
DCGAN:
目前GAN系列基本都基于DCGAN进行改进,是目前沿用的比较work的结构标配:
1) 去掉max pooling
2) 去掉fc层
3) 加入BN
4) generator输出加入tanh, 其他用RELU, discriminator中用leaky ReLU
Detail:

Improved GAN:
主要做了:
1) 特征匹配
2) disciminator对比的是一个batch中的差异性。
3) 增加参数约束项
4) 标签设置为0.1 / 0.9 而不是 0, 1
5) 提出了VBN, 相当于设置一个虚拟的集合,不断扩充这个样本空间做BN
Detail:

reference material: https://mp.weixin.qq.com/s?__biz=MzI1NTE4NTUwOQ==&mid=2650325876&idx=1&sn=5b30f8341f250be0147583b0ad18c689


Leave a Comment