Understand Autoencoder(1):Traditional AE
Published:
以下将分为4个部分介绍:
- ae基本概念
- ae训练方式
- ae特征如何做分类
- ae变体
1)先来理解autoencoder的基本概念:
自动编码器其实可以理解为是一种尽可能复现输入信号的神经网络,也可以认为自动编码器是可以像pca那样找到可以表征信息的主要成分,只不过这个过程是通过学习得到的.
Encoder的过程,按照理论上来说这个code其实就是包含了事物丰富的表征信息,而decoder则是负责解释和翻译这个表征.所以a/e可以分开训练.
2)再来看autoencoder的两种训练方式:
第一种 就是给定无标签数据,进行非监督学习表征
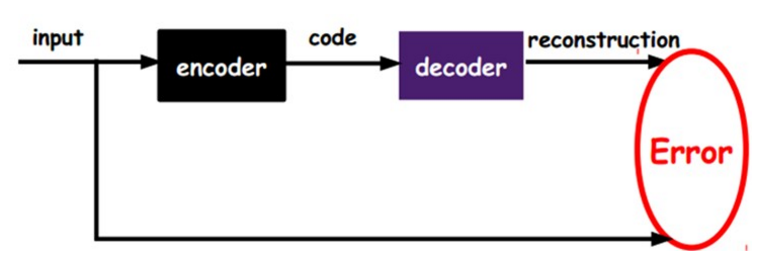
如上图,我们将input输入一个encoder编码器,就会得到一个code,这个code也就是输入的一个表示,那么我们怎么知道这个code表示的就是input呢?
我们加一个decoder解码器,这时候decoder就会输出一个信息,那么如果输出的这个信息和一开始的输入信号input是很像的(理想情况下就是一样的),那很明显,我们就有理由相信这个code是靠谱的。所以,我们就通过调整encoder和decoder的参数,使得重构误差最小,这时候我们就得到了输入input信号的第一个表示了,也就是编码code了。因为是无标签数据,所以误差的来源就是直接重构后与原输入相比得到。
第二种 通过编码器产生特征,然后训练下一层。这样逐层训练.
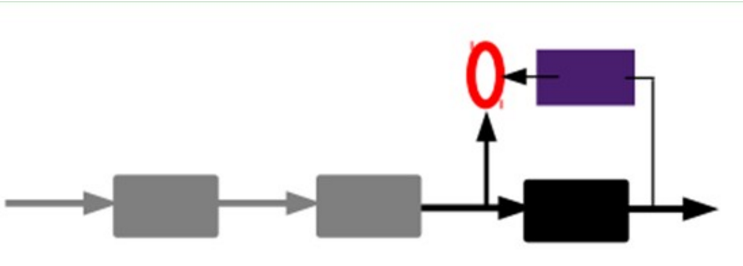
那上面我们就得到第一层的code,我们的重构误差最小让我们相信这个code就是原输入信号的良好表达了,或者牵强点说,它和原信号是一模一样的(表达不一样,反映的是一个东西)那第二层和第一层的训练方式就没有差别了,我们将第一层输出的code当成第二层的输入信号,同样最小化重构误差,就会得到第二层的参数,并且得到第二层输入的code,也就是原输入信息的第二个表达了。其他层就同样的方法炮制就行了 (训练这一层,前面层的参数都是固定的,并且他们的decoder已经没用了,都不需要了)。
3) 再来看一下,如何通过上面两种方法ae建立的表征来做分类:
既然已经训练好encoder,那么这个网络就可以得到一个良好代表输入的特征,这个特征可以最大程度上复原输入.
那么这个时候我们需要将最后层的特征code输入到最后的分类器,通过有标签样本,通过监督学习进行微调,这也分两种。
- 一个是只调整分类器(黑色部分)
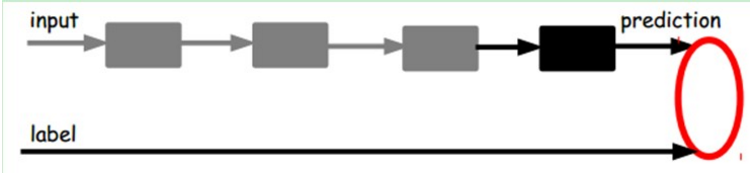
- 另一种:通过有标签样本,微调整个系统
4) AE变体
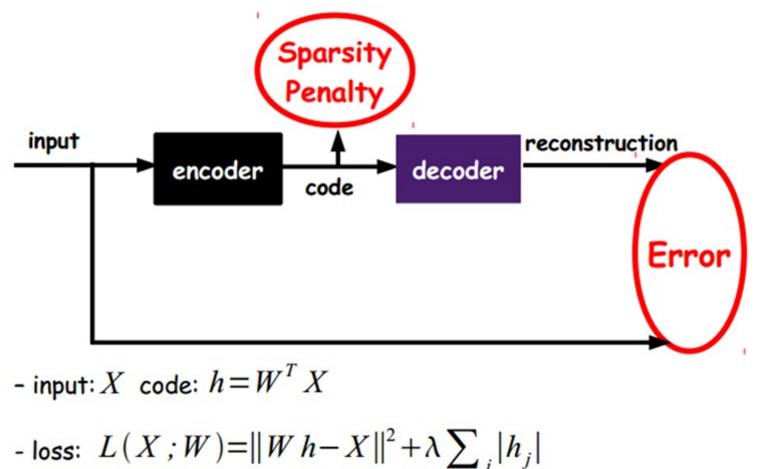
Sparse AE:
在ae基础上加上L1约束,限制每次得到的表达尽量稀疏,因为稀疏的表达往往比其他的表达有效
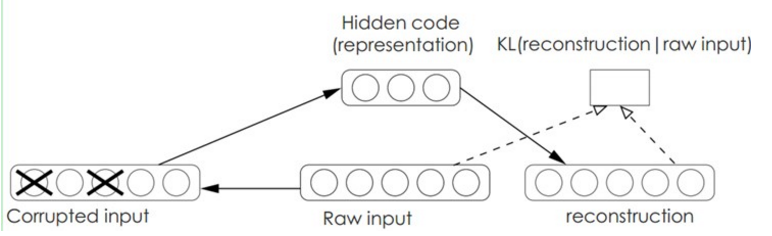
Denoise AE:
在ae的基础上,输入加入一个噪声,然后让编码器再重新重建出输入,无形中其实就学会了一个去除噪声的能力.
reference material: http://blog.csdn.net/u011534057/article/details/53261920



Leave a Comment