Universal Style Transfer via Feature Transforms
Published:

以下将分为3个部分介绍:
- 1.提出的background和sense
- 2.proposal network pipeline
- 3.results
Background
先来review一下过去的架构.
1.传统的neural style存在两个巨大的弊端: 调参/耗时。即不仅需要我们对neural style的层级进行大量调参,而且整个迭代过程是对于z噪声进行迭代,非常耗时。
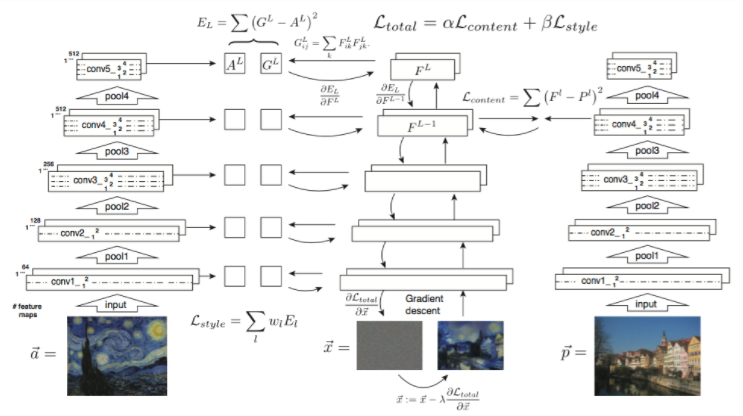
2.即使Texture Net和 Feifei Li在2016的工作中提出在前面承接一个G,将迭代过程变成一个网络来进行泛化style的学习,仍然避免不了调参。
即对于style和content loss 我们仍然需要通过对layer的尝试参数,来得到一个和style较为匹配的表述才能有较好的效果,且针对不同的style这一步骤需要重新training。
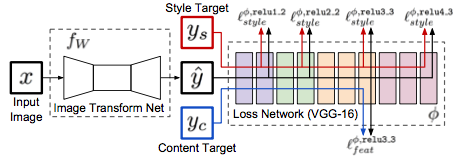
Sense
因此近期style transfer领域的作者都在思考一件事情,就是来探究是否能够进行泛化的特征style transfer 通过encoder/decoder来进行不需要训练的style transfer。 这篇文章就是一个较好的扩展。
Introduction of proposal network pipeline
文章提出了一个通用的reconstruction network,能够对任意输入的style进行transfer,而不需要重新训练。 其中主要insight的点在于三个:
1. 提出了WCT层 whitening & coloring transform layer:对于任意一个style image,要能够使得content能够表现出style风格,则只需feature map层级上分布表征一致。
Steps:
(实际和传统的color transfer的方式很相似)
1.首先将feature map减去均值,然后乘上对自身的协方差矩阵的逆矩阵,进行whitening, 将feature map拉到一个白化的分布空间。
2.然后通过对style image取得image feature map的coloring协方差矩阵,乘上content image 白化后的结果加上mean,即将content图白化后的feature map空间迁移到style图的分布上。
3.不断向上迭代,最后解码出来。
WCT:
Whitening Transform
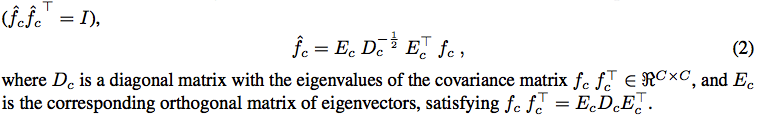
Coloring Transform
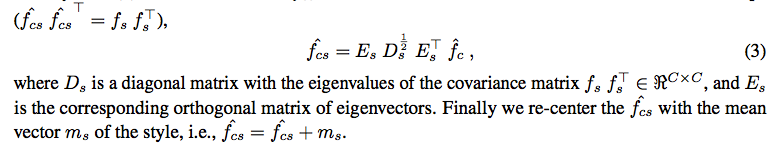
2.训练一个通用的decoder, 对于进行WCT后的feature map能够通用解码。
(实际和style swap思想基本一致,即训练出多个decoder,能够对于VGG不同层级的feature map进行deconvolution翻译到上一层直至原图,这里的作用为能够对于WCT后的feature map进行统一解码),训练数据是MSCOCO。
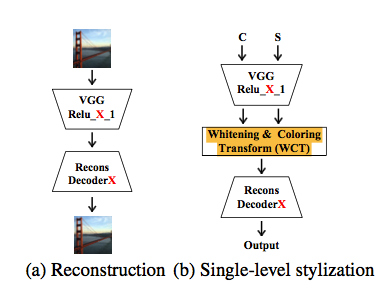
这边的 encoder 和 decoder 训练loss为:
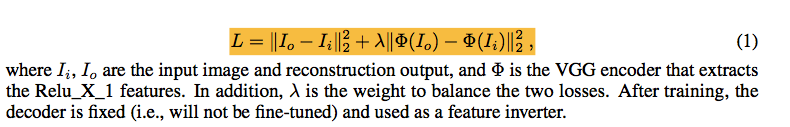
解释一下和style swap思想一致的训练重建vgg decoder的过程:
L1: 为Decoder - Relu4-1 -> 重建的 Relu5_1 和 VGG-19 Encoder的Relu5_1做loss (实际为一个有监督过程)
L2: 为Decoder - Relu4-1 和 通过重建的Relu5_1过VGG-19 Relu5_1 的Encoder后得到Relu4_1的结果做loss 使得Relu 4-1 的监督为一致。 (实际为一个无监督过程)
因此单层的WCT和训练出的重建encoder可将style结果重建为:

3.作者为了精化效果,采用了多层叠加coarse to fine的思想,类似与上一篇hierarchy multimodel transfer类似的思想来进行style transfer效果的refine.
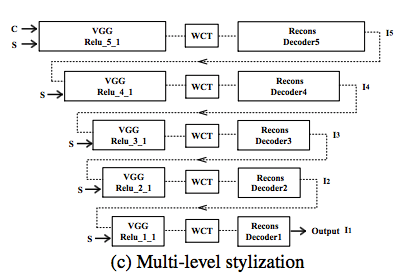
可以看到效果达到了预期,有了更好的style表现。
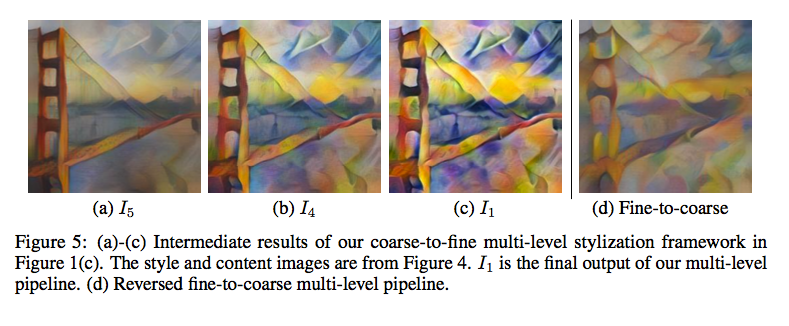
Results & Implement :
可以看到结果是不仅不需要调参 且笔触的表现都是非常不错de~
结合不同的mask,且不需要style的调优,只需要挑选到好的图就可以进行不错的整体的实时风格迁移和用户交互接口。



Leave a Comment