Deep Learning for Beginners
Published:

Introduction
Deep learning(deep structured learning, hierarchical learning or deep machine learning) is a branch of machine learning based on a set of algorithms that attempt to model high-level abst -ractions in data by using multiple processing layers, with complex structures or otherwise, composed of multiple non-linear transformations.
Here are some references about learning procedures from the perspective of beginners and sharing some resoures with deep learning about how beginners learned step by step.
*If there are some more better suggestions,please add following and help make it better :)
Table of Contents
- Step one: Mainly build up the basic sense of deep learning
- Step two: Notes of Basic Reference Paper for the beginners
- Step three : Install caffe and train your own model
Step one: Mainly build up the basic sense of deep learning
[1].Deep Learning Notes you can learn some basic senses about the deep learning
Including:
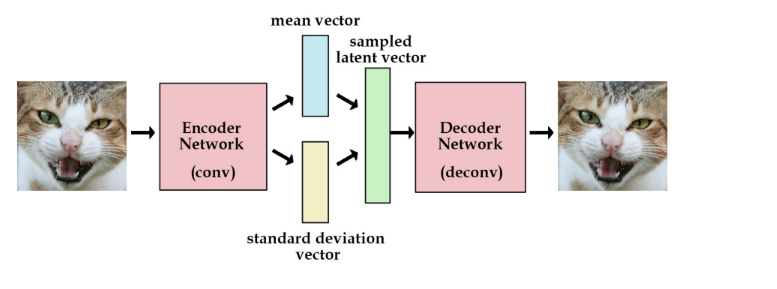
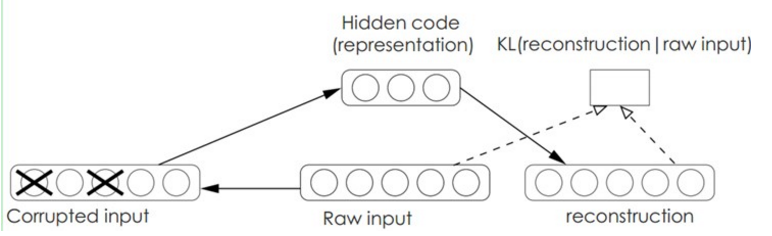
- AutoEncoder
- Sparse Coding
- Restricted Boltzmann Machine(RBM)
- Deep BeliefNetworks
- Convolutional Neural Networks
[2].Beginner Reference Papers and Books
Including:
- AlexNet
- GoogLeNet
- VGGNet
- Inception-v3
- ResNet
- Tensor
- Inception-v4
[3].The Deep Learning Playbook
Including:
- Libraries:
- Theano (Python)
- Libraries based on Theano: Lasagne, Keras, Pylearn2
- Caffe (C++, with Python wrapper)
- TensorFlow (Python, C++)
- Torch (Lua)
- ConvNetJS (Javascript)
- Deeplearning4j (Java)
- MatConvNet (Matlab)
- Projects / Demos:
- All the tutorials of your favorite library above
- Facial Keypoint Detection
- Deep Dream
- Eyescream
- Deep Q-network (Atari game player)
- Caffe to Theano Model Conversion (use Caffe pretrained model in Lasagne)
- R-CNN
- Fast R-CNN
- Plankton Classification (winning solution of National Data Science Bowl on Kaggle)
- Galaxy Classification (winning solution of Kaggle competition)
- University of Toronto Demos
- UFLDL Tutorial
- Deep Learning Google,2016
- More mathematics theory
- Machine Learning -Andrew Ng(Stanford University) 2009
- More exact examples
- Machine Learning -Andrew Ng(Stanford University) 2013
- Good Notes of Standford Machine Learning
- CS231n: Convolutional Neural Networks for Visual Recognition - Fei-Fei Li and Andrej Karpathy (Stanford University) 2016
- If you wanna learn more deeply reference coureses,please refer to the Coureses of WIKI PAGE awesomecvresources
[5].Deep Learning Reference Website
As comparing to the traditional feature extraction,here are some basic and useful papers on computer vision:
Including:
- SIFT Lowe ‘99
- Spin Images Johnson & Herbert ‘99
- Textons Malik et al. ‘99
- RIFT Lazebnik ‘04
- GLOH Mikolajczyk & Schmid ‘05
- HoG Dalal & Triggs ‘05
- SURF Bay et al. ‘06
- ImageNet Krizhevsky ‘12
Step two: Notes of Basic Reference Paper for the beginners
AlexNet:ImageNet Classification with Deep Convolutional Neural Networks
1.Testing dataset of this paper -> 1.2 million training images, 50,000 validation images, and 150,000 testing images(ILSVRC-2010)
results:
ILSVRC-2010  ILSVRC-2012
ILSVRC-2012 
2.architectecture

3.ReLU Nonlinearity
Following Nair and Hinton [20],this paper refers to neurons with this nonlinearity as Rectified Linear Units (ReLUs). Deep convolutional neural networks with ReLUs train several times faster than their equivalents with tanh units.

(On this dataset the primary concern is preventing overfitting, so the effect they are observing is different from the accelerated ability to fit the training set which we report when using ReLUs)
[20] V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In Proc. 27th International Conference on Machine Learning, 2010
4.Local Response Normalization
ReLUs have the desirable property that they do not require input normalization to prevent them from saturating.Response normalization reduces our top-1 and top-5 error rates by 1.4% and 1.2%,respectively
5.Overlapping Pooling
This scheme reduces the top-1 and top-5 error rates by 0.4% and 0.3%, respectively, as compared with the non-overlapping scheme s = 2, z = 2, which produces output of equivalent dimensions
6.two primary ways for combating overfitting
This neural network architecture has 60 million parameters,therefore,combat overfitting is a important problem
Data Augmentation:
The first form of data augmentation consists of generating image translations and horizontal reflections
- The second form of data augmentation consists of altering the intensities of the RGB channels in training images
- Dropout
- consists of setting to zero the output of each hidden neuron with probability 0.5,The neurons which are “dropped out” in this way do not contribute to the forward pass and do not participate in backpropagation.So every time an input is presented, the neural network samples a different architecture,but all these architectures share weights. This technique reduces complex co-adaptations of neurons,since a neuron cannot rely on the presence of particular other neurons.
- note:this paper recommand to use dropout in the first two fully-connected layers of figure architecture
more basic papers are waiting for adding…
Step three : Install caffe and train your own model
How to install caffe on winodws:Windows install caffe on VS2013.pdf
Recommend example:Alex’s CIFAR-10 tutorial, Caffe style
If you wanna try more examples,please refer to the example page of caffe
Step by step:
Including:
- 1.preparing your dataset
- 2.writing the solver file
- 3.defining your own model network
- 4.Training and Testing the Model
- 5.Observing the results.


Leave a Comment