E-net: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
Published:

About Segmentation Task:
在基于segmentation的这类framework上,和neural style(texture net)很相似,(encorder <-> decorder),虽然实际的task不同,但是在某些方面的网络设计和模型压缩时有很多值得去学习和借鉴的地方.
1.Introduction:
从FCN网络出来后,基本就奠定了后续基于分割的一套比较通用的framework。即
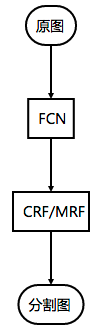
也就是说前端使用FCN使用特征粗提取,后端cascade一个color based segmentation或conditional random fields来优化输出,最后得到分割图。
reference materials: FCN-Fully Convolutional Networks for Semantic Segmentation
2.Network architecture:
image进来先用了一个initial的block,然后就是接带1x1卷积核进行升降维的bottleneck进行3个encoder循环(stage1包含5个bottleneck blocks,stage2/3和stage1一样的结构但是在输入开始部分没有downsamping)和2个decoder(stage4/stage5)设计,最后接一个C(object number)类的fullconv。
整个网络框架如下:


submodule reference:
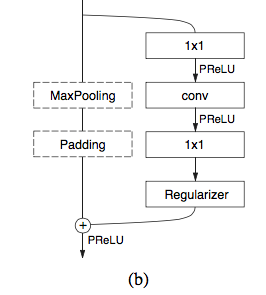
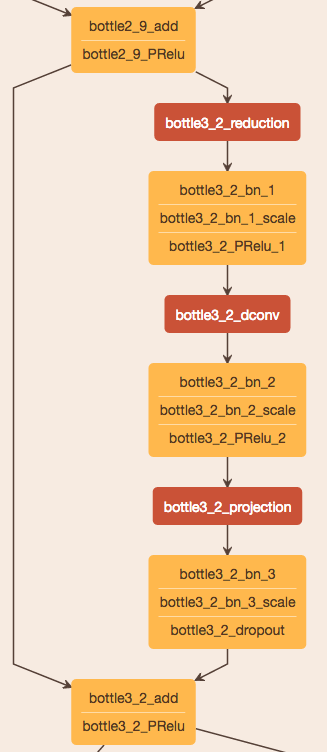

值得提到的一点是:作者在实际当中为了减少对kernal呼叫的次数,比如在cudnn中就对卷积和bias使用分离的卷积,和减少全局memory的操作,并未在projections中使用bias。 这样在实测中,并不影响结果的准确度,后续可以借鉴下这个方式来节省一些手机端上的操作。

3.Design Choices:
这部分是论文最精华的部分,作者做了大量的实验来证明为什么最终这样设计出ENet,其中的一些点在相似的task设计中具有很大的参考价值。
Drawbacks And Solutions:
1) Feature map resolution
在语义分割中的downsampling有两个很明显的缺点:
1.首先,downsapling其实会造成对空间上边缘形状的一些丢失
2.其次,全pixel级的分割要求最终的输出和输入是一样的分辨率,这样就会导致说,如果我们downsampling过重,就需要相应消耗更多的运算量在upsampling上。

但是在实际中,对downsmpled后的图像做filters operating的好处是会有更大的receptive field来获得更多的context。 这个对于只需要分辨物体是否属于不同类而言,是比较重要的。比如只需要区分在马路上的行人或者骑手,而不要求看清他们的脸这样的task。 因此,为了达到这样的效果,作者使用了dilated convolutions,这样就在保证网络的感受野的前提下,确保了图像语义分割的精度。
Reference Materials of Dilated Convolutions :
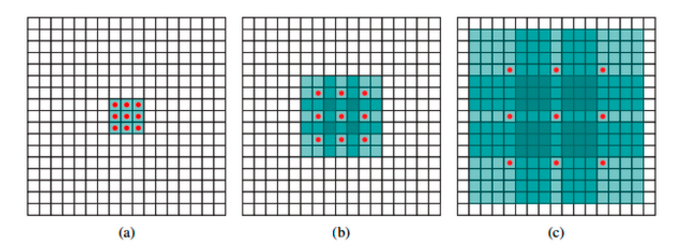
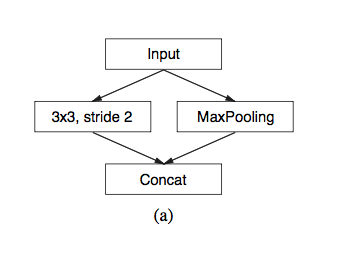
以3x3的卷积核为例,传统卷积核在做卷积操作时,是将卷积核与输入张量中“连续”的3x3的patch逐点相乘再求和(如上图a,红色圆点为卷积核对应的输入“像素”,绿色为其在原输入中的感知野)。而dilated convolution中的卷积核则是将输入张量3x3的patch隔一定的像素进行卷积运算。如上图b所示,在去掉一层池化层后,需要在去掉的池化层后将传统卷积层换做一个“dilation=2”的dilated convolution层,此时卷积核将输入张量每隔一个“像素”的位置作为输入patch进行卷积计算,可以发现这时对应到原输入的感知野已经扩大(dilate)为7x7;同理,如果再去掉一个池化层,就要将其之后的卷积层换成“dilation=4”的dilated convolution层,如图c所示。
2) Early downsampling
为了达到一个比较real-time的效果,实际上很明显,就是要减少一开始大图的运算量,然而大部分目前的框架都对这个不够重视。 而且,实际上这时候的视觉信息也是高度冗余的,因此作者提出了在最初的两个block中,大幅度的减少了input image size来压榨出最有效的表征部分。
3) Decoder size
不像segnet这样非常对称的结构,作者在网络设计时,使用更多的encoder,更少的decoder,因为作者认为实际上decoder的作用只是在对encoder的结果学习如何进行upsample,only fine-tuning the details。
4) Nonlinear operations
作者惊讶的发现移除掉网络一开始的layers的ReLUs可以优化结果,因为作者观察到在最初layers上的weights建立了比较大的variance并且对真实的values只有较轻微的biased波动。 (不太理解此部分= =..)

5)Information-preserving dimensionality changes
实际上,和之前说的早期对输入进行downsample是很有效的,但实际上直接这样激进地做会对信息有影响,所以作者替代了一般卷积后pooling,改为卷积操作的时候将stride设为2,再concate结果的feature map,达到了加速初始block 10倍的效果。
同时作者还发现了在原始ResNet框架上的一个问题: 就是当downsampling的时候,在卷积上第一个1x1 projection在dimensions上以2x2的stride可以有效的抛弃掉75%的输入。 如果增加filter的size到2x2,我们就能够将所有的输入考虑进来,以此来改善information flow和准确率。

6)Factorizing filters
作者在这边选择用了factorizing filters的方式,来尽量降低不同卷积之间weights冗余性。而且同时,bottleneck module的结构 (projection, convolution, projection),实际上也是在对一个大的卷积层进行一个分解。所以,可以理解为这样的一个结构实际上最大化了模型的能力。
Performance Analysis:
最终ENet达到了18x的加速,79x less参数`,并且达到了和现在模型相似或更好的结果。
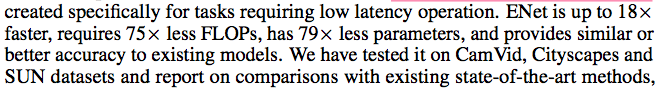
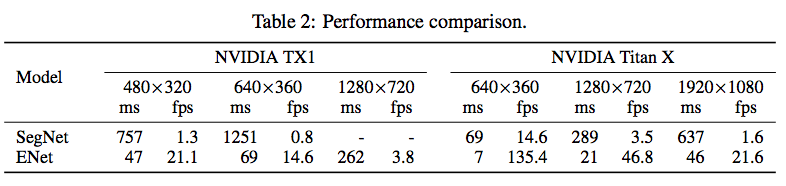
最终,设计出来的ENet基本可以达到接近于real time..真是又好又快又小阿.. :)))


Leave a Comment